One of the greatest advantages of classification trees is their
ability to handle missing data. For example, in a dataset of
geochemical analyses, some samples might have been analysed for major
and trace elements, while others were only analysed for trace elements
and stable isotopes. Yet another set of samples might have been
analysed for all elements except Zr, etc. Methods like discriminant
analysis cannot easily handle these situations, severely restricting
their applicability and power. Both for training and prediction, trees
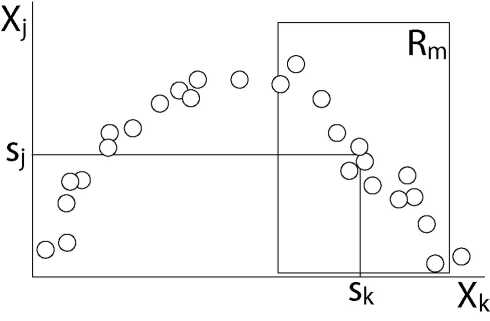
solve the missing data problem by ``surrogate splits''. Having chosen
the best primary predictor and split point (disregarding the missing
data), the first surrogate is the predictor and corresponding split
point that has the highest correlation with the primary predictor in
R![]() (Figure 2). The second surrogate is the
predictor that shows the second highest correlation with the primary
split variable and so forth.
(Figure 2). The second surrogate is the
predictor that shows the second highest correlation with the primary
split variable and so forth.
|