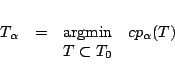Define the ``cost-complexity criterion'' of a tree T as
with ![]() T
T![]() the number of terminal nodes in T, N
the number of terminal nodes in T, N![]() the number of
observations in the m
the number of
observations in the m![]() terminal node, Q
terminal node, Q![]() (T) the ``node
impurity'' defined by Equation 1 and
(T) the ``node
impurity'' defined by Equation 1 and ![]() a tuning
parameter. For a given
a tuning
parameter. For a given ![]() 0, it is possible to find the
subtree T
0, it is possible to find the
subtree T
![]() T
T![]() that minimizes cp
that minimizes cp![]() (T) over
all possible subtrees of the largest possible tree T
(T) over
all possible subtrees of the largest possible tree T![]()
Repeating this procedure for a range of values 0
![]() produces a finite nested sequence of trees
{T
produces a finite nested sequence of trees
{T![]() ,T
,T![]() ,...,T
,...,T
![]() }. Except for T
}. Except for T![]() ,
these trees will no longer have only pure end-nodes. Impure end-nodes
are assigned the class that dominates in them. We then choose the
value
,
these trees will no longer have only pure end-nodes. Impure end-nodes
are assigned the class that dominates in them. We then choose the
value ![]() that minimizes an estimate of future prediction
error, for example by ``V-fold cross-validation''. The training data
are randomly divided into V (e.g., ten) fractions of equal size. We
then grow V overly large trees T
that minimizes an estimate of future prediction
error, for example by ``V-fold cross-validation''. The training data
are randomly divided into V (e.g., ten) fractions of equal size. We
then grow V overly large trees T![]() , each time using all but
the v
, each time using all but
the v![]() sample fraction. Each of these trees then goes through
the pruning procedure described before, yielding V nested sequences of
trees
{T
sample fraction. Each of these trees then goes through
the pruning procedure described before, yielding V nested sequences of
trees
{T![]() ,T
,T
![]() ,...T
,...T
![]() },
1
},
1![]() v
v![]() V. The trees T
V. The trees T
![]() were constructed without
ever seeing the cases in the v
were constructed without
ever seeing the cases in the v![]() fraction. Sending the v
fraction. Sending the v![]() fraction down T
fraction down T
![]() for each v=1,...,V thus yields an
independent estimate of the misclassification error.
for each v=1,...,V thus yields an
independent estimate of the misclassification error.
A plot of these cross-validated (CV) prediction errors versus the number of nodes in each of the nested subtrees shows a minimum at some point. As discussed before, trees with fewer nodes tend to have large bias, while the increased CV-cost of overly large trees is caused by their inflated variance. There typically exist several trees with CV-costs close to the minimum. Therefore, a ``1-SE rule'' is used, i.e., choosing the smallest tree whose CV misclassification cost does not exceed the minimum CV-cost plus one standard error of the CV-cost for the minimum CV-cost tree. An example of this procedure will be given in Section 3.